CNN Model Explainability with Grad-CAM
Deep learning models have become vital to the field of Computer Vision, and Artificial Intelligence. They have become the workhorse of modern machine learning algorithms. From image classification to image captioning, deep learning has been viewed as the most viable option.
However, how and why these models make predictions is a subject of on-going research. As a matter of fact, little is known about why a model correctly infers a dog as a dog; essentially, the ‘why’ they work is significantly obscure. Therefore, they are often treated as a black box, a cryptic tool of wonder.
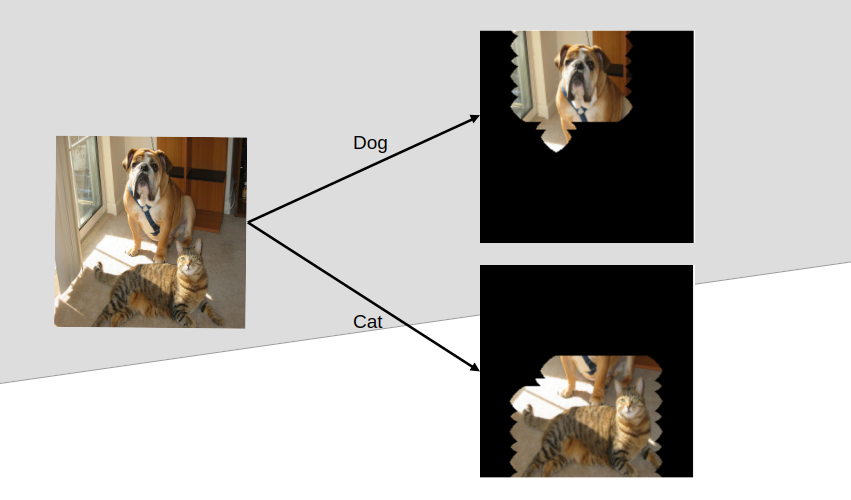
Model explainability or eXplainable AI (XAI) aims to provide a clear understanding of what led to a prediction through visual explanation. In this post, we introduce a notebook that use Gradient-weighted Class Activation Mapping (Grad-CAM) to implement model explainability in CNN for image classification with tensorflow. We then finally segmented the part crucial for the classification (a form of object localization).
The background: After training a well-performing image classifier for medical diagnostics with a post-graduate researcher, the need arose to see that the model really is considering the aspect of the image necessary for accurate prediction. It was pleasing to realize the model works correctly after obtaining the Grad-CAM. So, if you have been wondering what your DL model “looks” at to classify an image, then the notebook is for you.
Access the notebook here. I hope you enjoyed it.
Kindly note that this post will be updated later for analysis and detail.